For two years after GPT-4, every model OpenAI released was smaller. On February 27, 2025, that finally changed. OpenAI launched GPT-4.5, calling it "the next step in scaling the unsupervised learning paradigm." Here's what people thought:

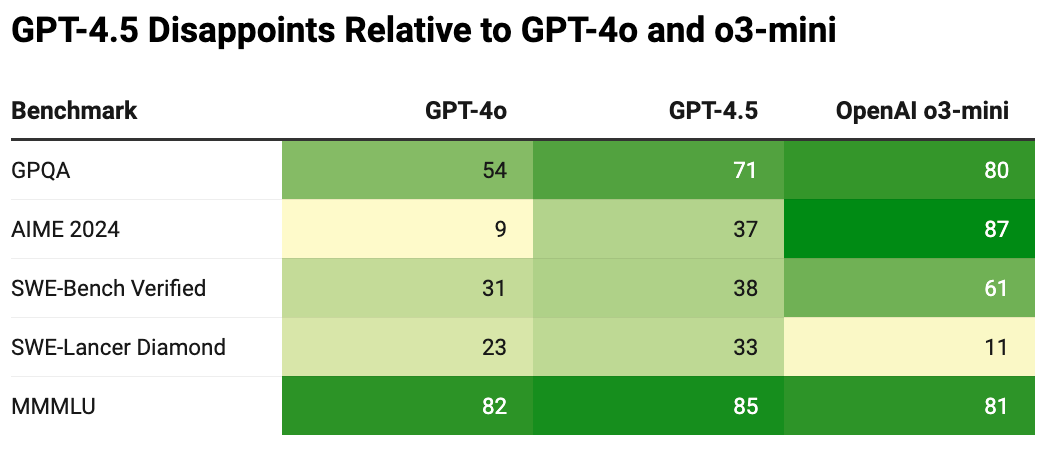
The launch video didn't do the model any favours. Rather than focusing on GPT-4.5's strengths, it highlighted how small the improvements were relative to GPT-4o and that it underperformed o3-mini, a 50x cheaper model.
Only a month and a half after the model's release, they announced it was going to be deprecated.
Why did GPT-4.5 disappoint?
When GPT-4 was released in 2023, it was seen as something fundamentally unprecedented. It exceeded GPT-3.5 substantially on most benchmarks, and in certain cases, reached human-level performance entirely.
GPT-4's launch also came with a developer livestream full of impressive feats that seemed unimaginable for GPT-3.5, such as converting hand-drawn sketches into functioning websites in a single prompt.
Where GPT-4 felt like a major breakthrough, GPT-4.5 felt disappointing.
The biggest contributor was the numerous models released between them. Just from OpenAI alone, there were updates to GPT-4, GPT-4 Turbo, multiple GPT-4o iterations, and the o-series reasoning models. This obscured gains from purely expanding pre-training compute between versions and raised questions: has pre-training reached its limits?
Is Pre-Training A Dead End?
To answer this question, we need to understand what occurs when we solely increase pre-training compute.
A useful comparison comes from Meta, which released eight different Llama 3 text-only language models in 2024. These range from 1B to 405B parameters, and given their release over just eight months, we can assume limited compute efficiency improvements occurred.
Using these models, we can establish a scaling correlation between pre-training compute amounts and benchmark results. This enables us to project GPT-4.5's expected performance relative to GPT-4, knowing it utilized roughly 10x more pre-training compute than its predecessor.1
The findings reveal that GPT-4.5 aligns with or potentially exceeds pre-training scaling trends:2




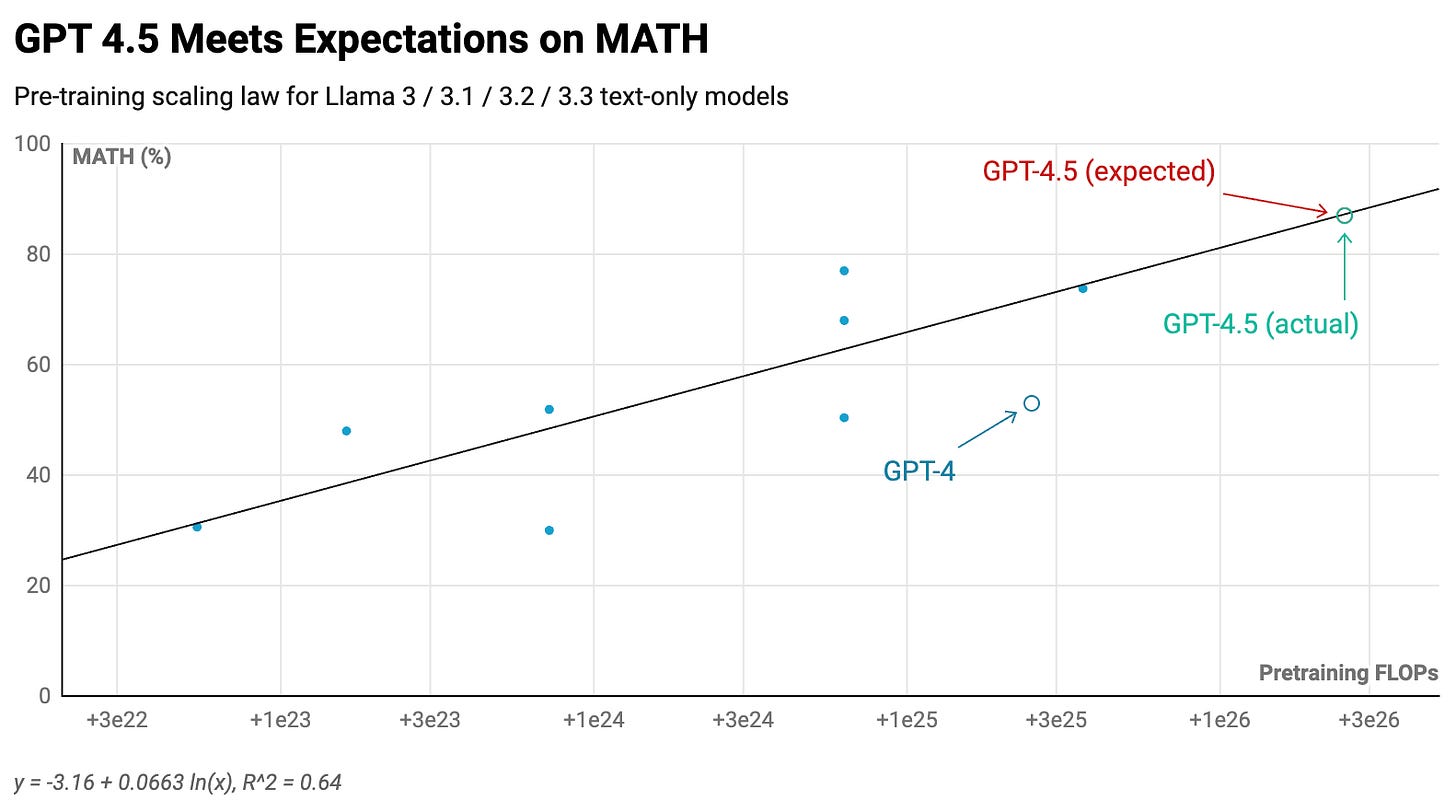
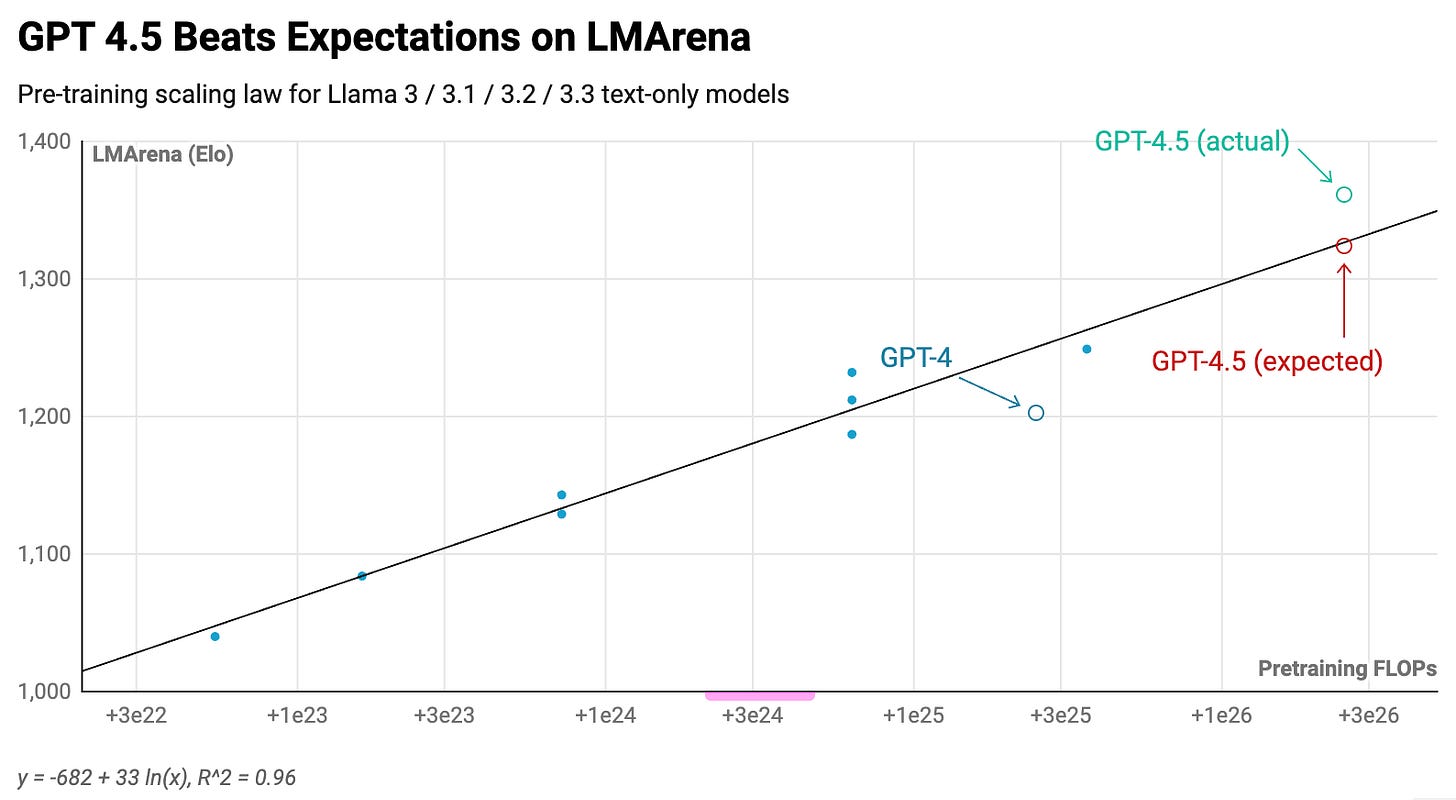


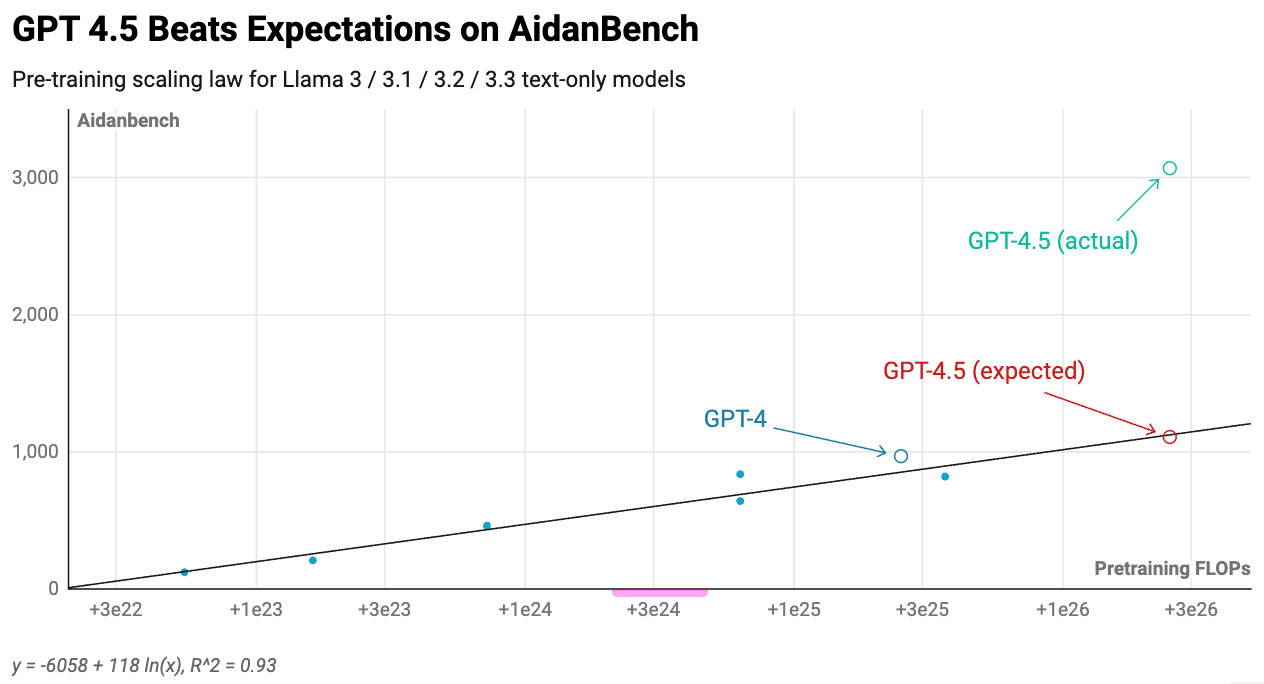
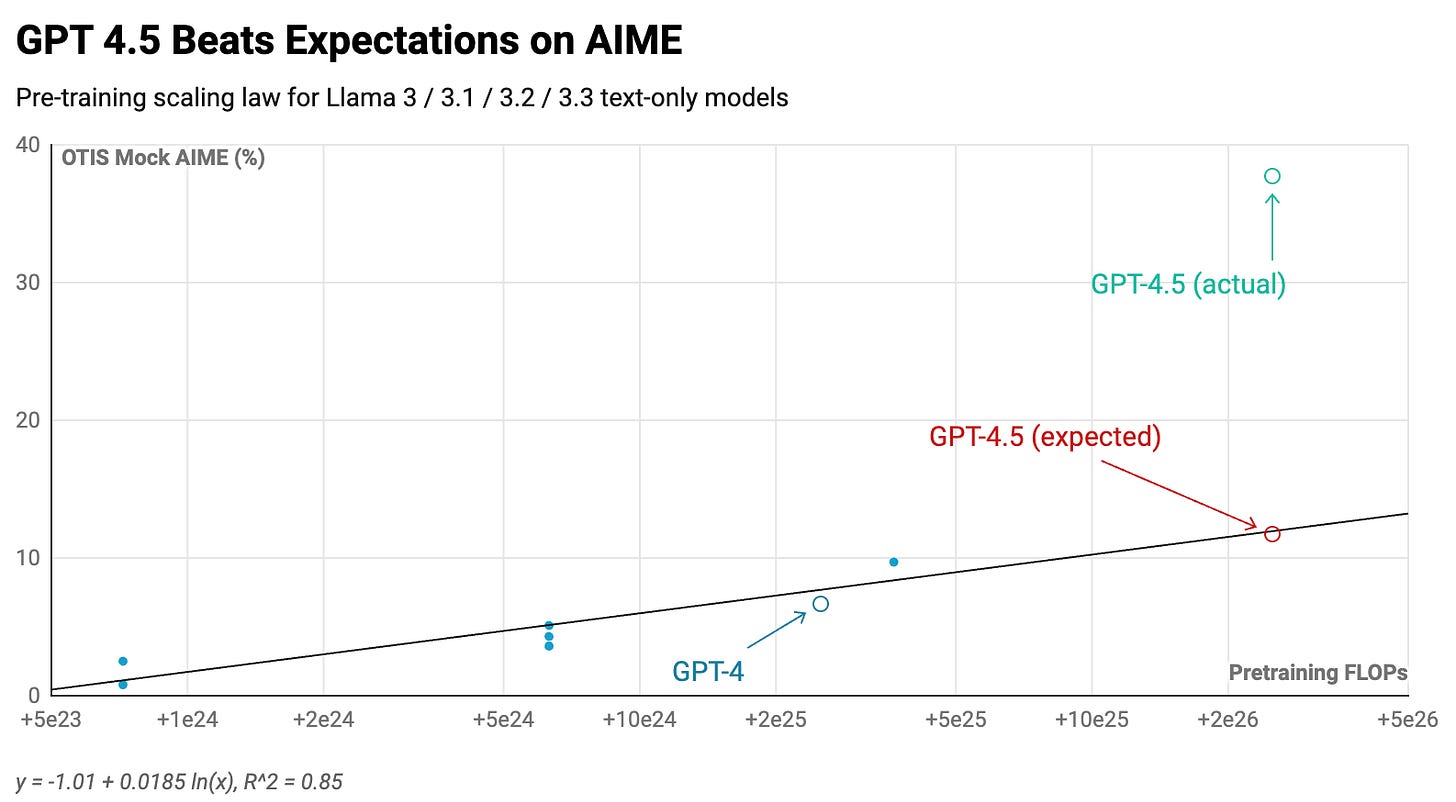

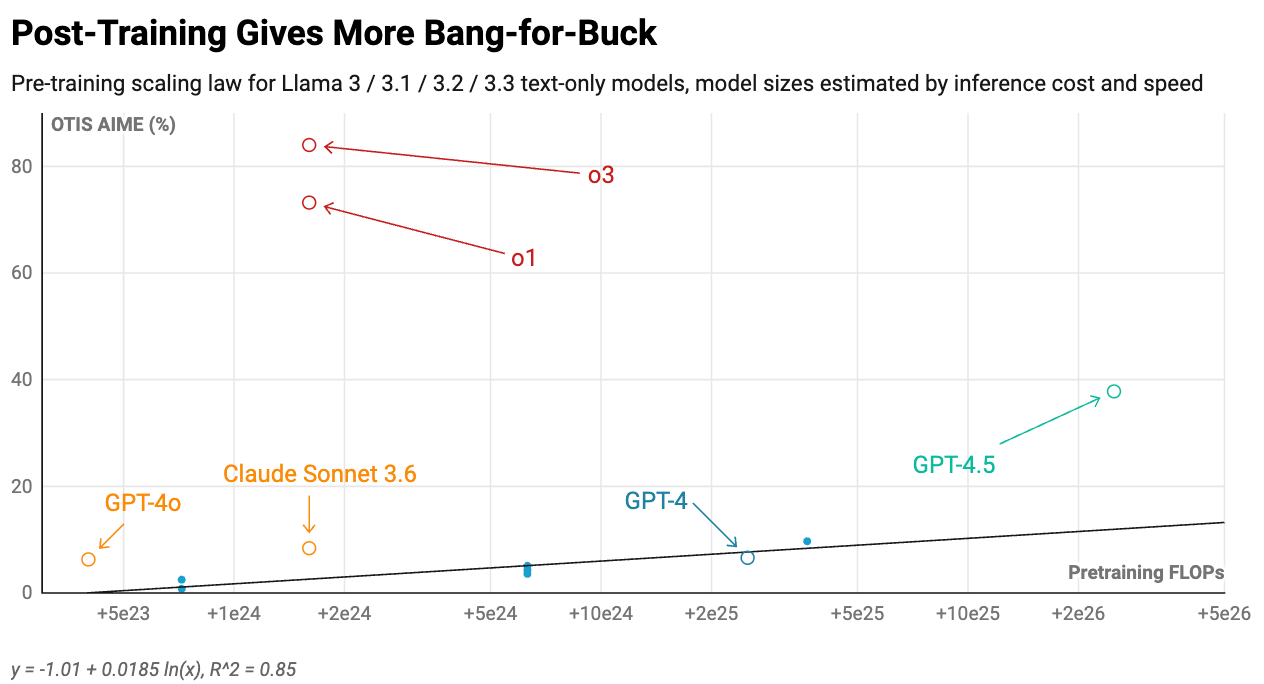



In summary, scaling remains effective. However, there's a compelling reason most frontier models have stayed smaller than GPT-4. Researchers discovered methods to achieve superior performance at substantially reduced expenses through other training stack components.
Consider mid-2024 models like GPT-4o and Claude Sonnet 3.6. They were 4 to 8 times smaller while maintaining equivalent or superior performance.3 Advancements in mid-training and post-training drove this:
- Enhanced annealing on superior quality, contextually distinct, or expanded-context information
- Instruction-tuning using synthetic data
- Preference-tuning incorporating human and AI feedback (reinforcement learning from human feedback)
Meanwhile, late 2024/early 2025 models like o1 and o3 demonstrated remarkable breakthroughs by implementing reinforcement learning on chains of thought (CoT).4
The Future of Model Training
Expanding RL and CoT proves remarkably successful for improvements in particular domains. Consequently, the near-term trajectory will pursue this direction. However, eventually the industry will shift its attention back to pre-training.
This stems from economic considerations regarding model deployment.
First, when clients have varied use cases, extensive RL training across numerous domains becomes necessary. RL in one area frequently diminishes unconnected capabilities. Models tuned through RLHF for dialogue perform worse at chess compared to equivalents closer to pre-trained states, and anecdotally, Claude 3.7 Sonnet exhibits more reward-optimization artifacts than its predecessor. Extensive RL training carries substantial expenses.
Second, when customers leverage numerous CoT tokens during inference, serving becomes prohibitively costly. A larger, more capable model requiring fewer CoT tokens for equivalent answers will eventually become more economical.5
It would be significantly cheaper to develop a model combining broader domain intelligence with enhanced absolute reasoning capability, reducing tokens needed at inference. Pre-training achieves precisely this outcome.6
Therefore, pre-training will eventually return as the primary focus, and computational requirements will continue expanding. Pre-training isn't gone — it's temporarily dormant.